Download, query, filter, and visualize Europe’s 322 million building
footprints — with runnable code for GeoPandas, DuckDB, and more. Every cell
below is taken straight from the notebook, outputs included.
# Alternatively, use the AWS CLI to download the file:
aws s3 cp s3://eubucco/v0.2/buildings/parquet/nuts_id=CH04/CH04.parquet . \
--endpoint-url https://s3.eubucco.com \
--no-sign-request
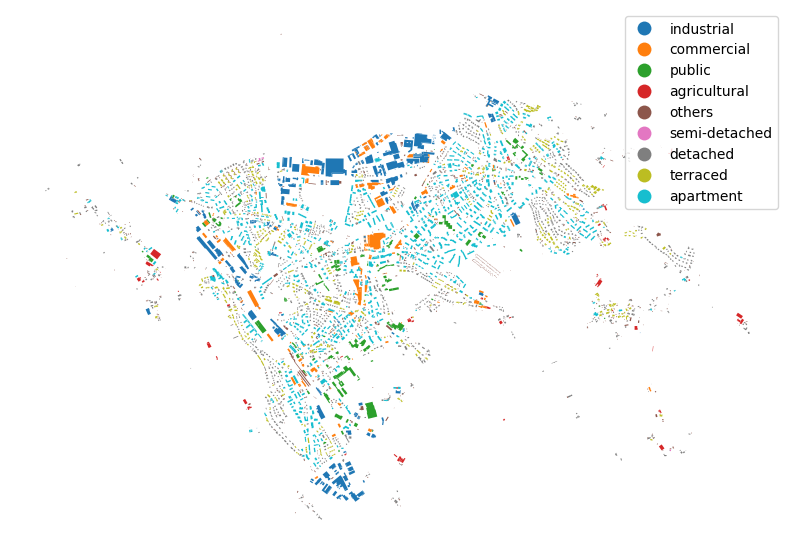
importgeopandasasgpd# Fetch data with WKB-encoded geometriesregion="CH04"s3_path=f"s3://eubucco/v0.2/buildings/parquet/nuts_id={region}/{region}.parquet"query=f""" SELECT * EXCLUDE geometry, ST_AsWKT(geometry) AS geometry FROM '{s3_path}' """df=con.execute(query).df()# Convert to GeoDataFramegdf=gpd.GeoDataFrame(df,geometry=gpd.GeoSeries.from_wkt(df["geometry"]),crs="EPSG:3035",)
Derive metadata
python
gdf["country"]=gdf["region_id"].str[:2]# EU VAT 2-digit country codegdf["NUTS1"]=gdf["region_id"].str[:3]# EU NUTS1 codegdf["block_id"]=gdf["id"].str.split("-").str[0]# Identify touching buildingsgdf["type_is_authoritative"]=gdf["type_source"].str.contains("gov")# Identify buildings with authoritative type informationgdf["type_is_merged"]=(gdf["geometry_source"]!=gdf["type_source"])&(gdf["type_source"]!="estimated")# Identify buildings with merged type informationgdf["type_is_estimated"]=gdf["type_source"]=="estimated"# Identify buildings with estimated type informationgdf["type_is_inferred"]=gdf["geometry_source"]!=gdf["type_source"]# Identify buildings with type being merged or estimated
# Categorical: Correct type in >80% of casesreliable_type=gdf[gdf["type_confidence"].fillna(1.0)>0.8]# Numerical: Precise height (uncertainty interval < 2m)precise_height=gdf[(gdf["height_confidence_upper"]-gdf["height_confidence_lower"]).fillna(0.0)<2.0]precise_height[["id","height","height_source","height_confidence_lower","height_confidence_upper"]].sample(3)
Output
id
height
height_source
height_confidence_lower
height_confidence_upper
188645
98baed995c394750-0
9.8
gov-switzerland
None
None
6773
60a2a6f495fb4e12-0
6.3
estimated
5.8
6.7
230851
2c825f0aca48467c-0
5.5
gov-switzerland
None
None
Filter data (while loading)
Filter based on attributes and region
python
# Extract buildings in France taller than 50ms3_path="s3://eubucco/v0.2/buildings/parquet/*/*.parquet"query=f""" SELECT * FROM read_parquet('{s3_path}', hive_partitioning = true) WHERE nuts_id LIKE 'FR%' AND height > 50 LIMIT 10"""df=con.execute(query).df()df[["id","region_id","height"]]
Output
id
region_id
height
0
108d4bd7a74040c9-0
FR101
65.0
1
3b7e6afc92744131-0
FR101
60.0
2
e89b7be2736e4169-0
FR101
65.0
3
4daaaf16b1b54bfc-0
FR102
55.0
4
8ed075685334418b-0
FR102
51.0
5
c369bcc13a154016-0
FR102
55.8
6
c35813798c9f4162-0
FR102
55.0
7
546c9c84c5b346b5-0
FR102
51.0
8
609e7f2534974b68-0
FR102
95.0
9
9ce5dcfe94a343a3-0
FR102
53.0
Spatial filtering
python
# Extract buildings within bounding box (bbox needs to be in EPSG:3035)s3_path="s3://eubucco/v0.2/buildings/parquet/*/*.parquet"query=f""" SELECT * FROM read_parquet('{s3_path}', hive_partitioning = true) WHERE bbox.xmin >= 5300000 AND bbox.xmax <= 5400000 AND bbox.ymin >= 1880000 AND bbox.ymax <= 1920000 LIMIT 10"""df=con.execute(query).df()df[["id","region_id","subtype","height","geometry_source"]]
Output
id
region_id
subtype
height
geometry_source
0
05d37030ab874ec1-0
EL541
others
5.1
msft
1
0bc0005f72494fd7-0
EL541
detached
5.4
msft
2
0cdd11ae251849b2-0
EL541
agricultural
5.4
msft
3
0ec6ff77f9924920-0
EL541
detached
5.9
msft
4
12eec1f43e3242d2-0
EL541
detached
5.2
msft
5
183053df36f74b91-0
EL541
detached
5.5
msft
6
372fd27c76994c5e-0
EL541
detached
6.0
msft
7
42b90d2ae23344b3-0
EL541
detached
6.3
msft
8
43b49459e1c64cba-0
EL541
others
5.2
msft
9
43b49459e1c64cba-1
EL541
detached
5.2
msft
Source filtering & country-level counts across Europe
python
# Count governmental buildings across Europes3_path="s3://eubucco/v0.2/buildings/parquet/*/*.parquet"query=f""" SELECT count(*) AS gov_count, LEFT(region_id, 2) AS country FROM read_parquet('{s3_path}', hive_partitioning = true) WHERE geometry_source NOT IN ('msft', 'osm') GROUP BY country ORDER BY gov_count DESC"""count=con.execute(query).df()count
Output
gov_count
country
0
61785354
DE
1
47813048
FR
2
16305302
ES
3
15963070
IT
4
14407294
PL
5
9677792
NL
6
8208819
BE
7
5677226
DK
8
5404654
FI
9
3979152
CZ
10
3488619
SK
11
2626901
CH
12
1927402
LT
13
1178551
SI
14
801576
EE
15
714354
AT
16
563224
CY
17
144088
LU
18
136030
MT
Analyzing regional stats
Download precomputed region-stats.parquet file from https://eubucco.com/files/.
stats["height_coverage"]=stats["n_gt_height"]/stats["n"]tooltip=["n","n_gov","n_osm","n_msft","n_gt_type","n_gt_subtype","n_gt_height","n_gt_floors","n_floors_0_3","n_floors_4_6","n_floors_7_inf","n_type_residential","n_type_non_residential",]stats["n"]=stats["n"].div(1000).round()stats.explore("n",legend=True,tiles="CartoDB positron",cmap="Blues",legend_kwds={"caption":"Number of Buildings (in thousands)"},tooltip=tooltip,)
Output
H3-grid aggregation and visualization
python
# Simple aggregated visualization with H3 hexagonsimporth3pandasgdf_floor=gdf[["geometry","height"]].copy()gdf_floor["height"]=gdf_floor["height"].astype(float)gdf_floor["floor_area"]=((gdf_floor.area*gdf_floor["height"])/1000/1000).round(2)gdf_floor["geometry"]=gdf_floor.centroid.to_crs("EPSG:4326")h3_grid=gdf_floor.h3.geo_to_h3_aggregate(resolution=8,operation="sum")# precisionh3_grid.explore(column="floor_area",cmap="YlGn",tiles="CartoDB positron",tooltip=["floor_area"],legend=True,)
Output
python
con.execute("INSTALL h3 FROM community; LOAD h3;")s3_path="s3://eubucco/v0.2/buildings/parquet/*/*.parquet"h3_resolution=5query=f"""WITH buildings AS ( SELECT height, ST_Transform( ST_Point( (bbox.ymin + bbox.ymax) / 2, (bbox.xmin + bbox.xmax) / 2 ), 'EPSG:3035', 'EPSG:4326' ) AS centroid FROM read_parquet('{s3_path}', hive_partitioning = true) WHERE height IS NOT NULL LIMIT 1000000 -- comment out to run query at scale),h3_stats AS ( SELECT h3_latlng_to_cell_string( ST_X(centroid), ST_Y(centroid),{h3_resolution} ) AS h3, AVG(height) AS avg_height, COUNT(*) AS n_buildings FROM buildings GROUP BY h3)SELECT h3, avg_height, n_buildings, h3_cell_to_boundary_wkt(h3) AS geometryFROM h3_stats"""df=con.execute(query).df()h3_grid=gpd.GeoDataFrame(df,geometry=gpd.GeoSeries.from_wkt(df["geometry"]),crs="EPSG:4326",)h3_grid[h3_grid["n_buildings"]>100].explore(column="avg_height",vmax=20,cmap="YlOrRd",tiles="CartoDB positron",legend=True,tooltip=["avg_height","n_buildings"],)
Output
Try it yourself — no install required
Live SQL on the EUBUCCO data lake from your browser
This runs DuckDB-WASM
in your browser and reads an EUBUCCO region file (the Zürich region, CH04)
straight over HTTP — no download, no backend. Edit the SQL and hit run.